Diferencia entre Big Data y Hadoop

Diferencia clave: Big Data vs Hadoop
Los datos se recopilan ampliamente en todo el mundo. Esta gran cantidad de datos se denomina big data o big data y no puede ser manejado mediante dispositivos de almacenamiento regulares. Hadoop Software Framework, que es un marco de código abierto por parte de Apache Software Foundation, se puede utilizar para superar este problema. El diferencia clave Entre Big Data y Hadoop es que Big Data es una gran cantidad de datos complejos, mientras que Hadoop es un mecanismo para almacenar Big Data de manera efectiva y eficiente.
CONTENIDO
1. Descripción general y diferencia de claves
2. ¿Qué es Big Data?
3. Que es Hadoop
4. Similitudes entre Big Data y Hadoop
5. Comparación de lado a lado: Big Data vs Hadoop en forma tabular
6. Resumen
¿Qué es Big Data??
Los datos se producen diariamente y en grandes cantidades. Es importante almacenar los datos recopilados en consecuencia y analizarlos para obtener mejores resultados. Google, Facebook recopila una gran cantidad de datos diariamente. Organizar los datos y analizarlos puede traer beneficios a la organización. En un banco, es esencial analizar datos para comprender la información del cliente, las transacciones, los problemas del cliente. Analizar estos datos y desarrollar soluciones mejorará la ganancia. Esto muestra que los datos están desempeñando un papel vital para que una organización funcione de manera eficiente y efectiva. A medida que los datos están creciendo rápidamente, las bases de datos relacionales o los dispositivos de almacenamiento regulares no son suficientes. Este tipo de una gran colección de datos que es difícil de almacenar y procesar puede nombrarse como Big Data o Big Data.
Big data
Big Data tiene tres propiedades. Son volumen, velocidad y variedad. En primer lugar, Big Data es un gran volumen de datos. Estos datos pueden tomar el volumen de bytes giga, bytes tera o incluso más que eso. El segundo atributo es la velocidad. Es la velocidad a la que se generan los datos. Esta es una propiedad importante en el análisis de los cambios ambientales y para detectar aviones. Los datos deben ser precisos y continuos en esas situaciones. Es un factor considerable tomar decisiones en tiempo real. Otra propiedad principal es la variedad, que describe el tipo de datos. Los datos pueden tomar formato de texto, video, audio, imagen, formato XML, datos del sensor, etc.
Que es Hadoop?
Es un marco de código abierto por parte de Apache Software Foundation para almacenar grandes datos en un entorno distribuido para procesar paralelo. Tiene un almacenamiento de distribución efectivo con un mecanismo de procesamiento de datos. El sistema de almacenamiento de Hadoop se conoce como Sistema de archivos distribuido Hadoop (HDFS). Divide los datos entre algunas máquinas. Hadoop sigue la arquitectura maestra-esclave. Se llama al nodo maestro Nodo y se llaman esclavos Nodos de datos. Los datos se distribuyen entre todos los nodos de datos.
El algoritmo principal que se está utilizando para procesar datos en Hadoop se llama mapa Reducir. Usando programas de reducción de mapas, los trabajos se pueden enviar a nodos esclavos. El idioma predeterminado para escribir programas de reducción de mapas es Java, pero también se pueden usar otros idiomas. Los nodos de datos o los nodos esclavos realizarán la tarea de análisis y enviarán el resultado al nodo/nodo maestro. Nodo/nodo maestro tiene un rastreador de trabajo para ejecutar el mapa Reducir trabajos en nodos esclavos. Los nodos de esclavos/nodos de datos tienen un rastreador de tareas para completar el análisis de datos y para enviar el resultado al nodo maestro.
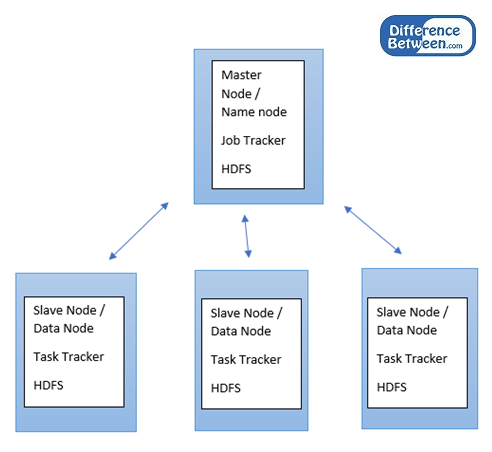
Arquitectura de Hadoop
Hadoop tiene algunas ventajas. Reduce el costo, la complejidad de los datos y aumenta la eficiencia. Es fácil agregar otra máquina al clúster Hadoop.
¿Cuál es la similitud entre Big Data y Hadoop??
- Tanto Big Data como Hadoop están relacionados con grandes sumas de datos.
¿Cuál es la diferencia entre Big Data y Hadoop??
Big Data vs Hadoop | |
| Big Data es una gran colección de complejos y variedad de datos que es difícil de almacenar y analizar utilizando métodos de almacenamiento tradicionales. | Hadoop es un marco de software para almacenar y procesar big data de manera efectiva y eficiente. |
| Significado | |
| Big Data no tiene mucho significado. | Hadoop puede hacer que Big Data sea más significativo y es útil para el aprendizaje automático y el análisis estadístico. |
| Almacenamiento | |
| Big data es difícil de almacenar, ya que consiste en una variedad de datos, como datos estructurados y no estructurados. | Hadoop utiliza el sistema de archivos distribuido (HDFS) de Hadoop que permite almacenar una variedad de datos. |
| Accesibilidad | |
| Acceder a Big Data es difícil. | Hadoop permite acceder y procesar Big Data más rápido. |
Resumen -Grande Datos vs Hadoop
Los datos están creciendo rápidamente. Las organizaciones gubernamentales y empresariales están recopilando datos. Analizar datos es extremadamente valioso. Una sola computadora no es suficiente para almacenar una gran cantidad de datos. Esta gran cantidad de datos complejos se denomina big data. Por lo tanto, Big Data se puede distribuir entre algunos nodos usando Hadoop. La diferencia entre Big Data y Hadoop es que Big Data es una gran cantidad de datos complejos y Hadoop es un mecanismo para almacenar Big Data de manera efectiva y eficiente.
Descargue la versión PDF de Big Data vs Hadoop
Puede descargar la versión PDF de este artículo y usarla para fines fuera de línea según la nota de cita. Descargue la versión PDF aquí Diferencia entre Big Data y Hadoop
Referencia:
1."¿Qué es Big Data y por qué importa?."¿Qué es Big Data?? | Sas us. Disponible aquí
2.El punto, tutoriales. "Hadoop - Descripción general de Big Data."Tutorials Point, 15 de agosto. 2017. Disponible aquí
3.El punto, tutoriales. "Descripción general de análisis de big data."Tutorials Point, 15 de agosto. 2017. Disponible aquí
4."¿Cuál es la diferencia entre Big Data y Hadoop?"Techopedia.comunicarse. Disponible aquí
5.thippireddybharath. "Big Data y Hadoop Introducción rápida."YouTube, YouTube, 12 de agosto. 2014. Disponible aquí
Imagen de cortesía:
1.'BigData 2267 × 1146 Trasparent' por Camelia.Boban - Trabajo propio, (CC By -SA 3.0) a través de Commons Wikimedia