Diferencia entre la agrupación y la clasificación
El diferencia clave entre la agrupación y la clasificación es que La agrupación es una técnica de aprendizaje no supervisada que agrupa instancias similares sobre la base de las características, mientras que la clasificación es una técnica de aprendizaje supervisada que asigna etiquetas predefinidas a instancias sobre la base de las características.
Aunque la agrupación y la clasificación parecen ser procesos similares, hay una diferencia entre ellos basado en su significado. En el mundo de la minería de datos, la agrupación y la clasificación son dos tipos de métodos de aprendizaje. Ambos métodos caracterizan los objetos en grupos por una o más características.
CONTENIDO
1. Descripción general y diferencia de claves
2. Que es la agrupación
3. ¿Qué es la clasificación?
4. Comparación de lado a lado: clúster vs clasificación en forma tabular
5. Resumen
Que es la agrupación?
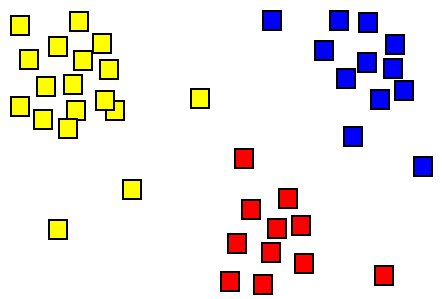
La agrupación es un método para agrupar objetos de tal manera que los objetos con características similares se unen, y los objetos con características diferentes se separan. Es una técnica común para el análisis de datos estadísticos para el aprendizaje automático y la minería de datos. El análisis y la generalización de datos exploratorios también es un área que utiliza la agrupación.
Figura 01: agrupación
La agrupación pertenece a la minería de datos no supervisada. No es un algoritmo específico único, pero es un método general para resolver una tarea. Por lo tanto, es posible lograr la agrupación utilizando varios algoritmos. El algoritmo de clúster apropiado y la configuración de los parámetros dependen de los conjuntos de datos individuales. No es una tarea automática, pero es un proceso iterativo de descubrimiento. Por lo tanto, es necesario modificar el procesamiento de datos y el modelado de parámetros hasta que el resultado logre las propiedades deseadas. La agrupación de K-means y la agrupación jerárquica son dos algoritmos de agrupación comunes en la minería de datos.
¿Qué es la clasificación??
La clasificación es un proceso de categorización que utiliza un conjunto de datos de capacitación para reconocer, diferenciar y comprender los objetos. La clasificación es una técnica de aprendizaje supervisada donde un conjunto de capacitación y observaciones correctamente definidas están disponibles.
Figura 02: Clasificación
El algoritmo que implementa la clasificación es el clasificador, mientras que las observaciones son las instancias. El algoritmo vecino de K-nearest y los algoritmos de árboles de decisión son los algoritmos de clasificación más famosos en la minería de datos.
¿Cuál es la diferencia entre la agrupación y la clasificación??
La agrupación es un aprendizaje no supervisado, mientras que la clasificación es una técnica de aprendizaje supervisada. Agrupe instancias similares sobre la base de las características, mientras que la clasificación asigna etiquetas predefinidas a instancias sobre la base de las características. La agrupación divide el conjunto de datos en subconjuntos para agrupar las instancias con características similares. No usa datos etiquetados o un conjunto de capacitación. Por otro lado, clasifique los nuevos datos de acuerdo con las observaciones del conjunto de capacitación. El conjunto de entrenamiento está etiquetado.
El objetivo de la agrupación es agrupar un conjunto de objetos para encontrar si existe alguna relación entre ellos, mientras que la clasificación tiene como objetivo encontrar a qué clase un nuevo objeto pertenece del conjunto de clases predefinidas.
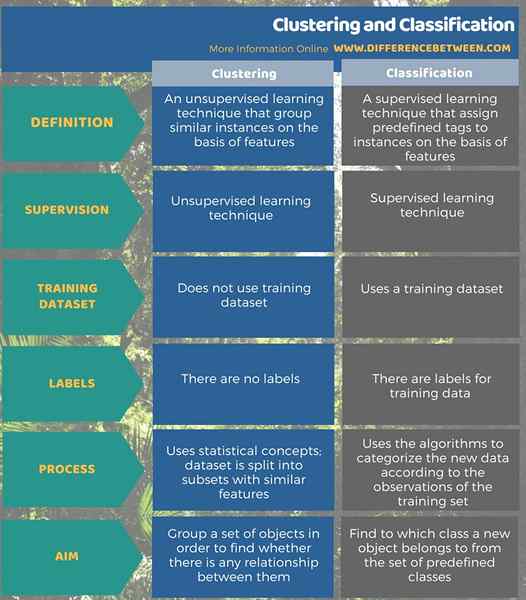
Resumen -Clustering vs Classificación
La agrupación y la clasificación pueden parecer similares porque ambos algoritmos de minería de datos dividen el conjunto de datos en subconjuntos, pero son dos técnicas de aprendizaje diferentes, en la minería de datos para obtener información confiable de una recopilación de datos sin procesar. La diferencia entre la agrupación y la clasificación es que la agrupación es una técnica de aprendizaje no supervisada que agrupa instancias similares sobre la base de las características, mientras que la clasificación es una técnica de aprendizaje supervisada que asigna etiquetas predefinidas a instancias sobre la base de características.
Imagen de cortesía:
1."Cluster-2" por clúster-2.GIF: infernal Trabajo derivado: (dominio público) a través de Wikimedia Commons 2."Magnetismo" de John Apropiado - Propio trabajo. (Dominio público) a través de Wikimedia Commons