Diferencia entre el aprendizaje automático supervisado y no supervisado

Diferencia clave: supervisado VS No supervisado Aprendizaje automático
El aprendizaje supervisado y el aprendizaje no supervisado son dos conceptos centrales de aprendizaje automático. El aprendizaje supervisado es una tarea de aprendizaje automático de aprender una función que asigna una entrada a una salida basada en el ejemplo de pares de entrada-salida de entrada. El aprendizaje no supervisado es la tarea de aprendizaje automático de inferir una función para describir la estructura oculta a partir de datos no marcados. El diferencia clave Entre el aprendizaje automático supervisado y no supervisado es que El aprendizaje supervisado utiliza datos etiquetados mientras el aprendizaje no supervisado utiliza datos no etiquetados.
El aprendizaje automático es un campo en informática que brinda la capacidad de que un sistema informático aprenda de los datos sin ser programado explícitamente. Permite analizar los datos y predecir patrones en él. Hay muchas aplicaciones de aprendizaje automático. Algunos de ellos son reconocimiento facial, reconocimiento de gestos y reconocimiento de voz. Hay varios algoritmos relacionados con el aprendizaje automático. Algunos de ellos son regresión, clasificación y agrupación. Los lenguajes de programación más comunes para desarrollar aplicaciones basadas en el aprendizaje automático son R y Python. También se pueden usar otros idiomas como Java, C ++ y Matlab.
CONTENIDO
1. Descripción general y diferencia de claves
2. Lo que es el aprendizaje supervisado
3. ¿Qué es el aprendizaje sin supervisión?
4. Similitudes entre el aprendizaje automático supervisado y no supervisado
5. Comparación de lado a lado: aprendizaje automático supervisado frente a no supervisado en forma tabular
6. Resumen
Lo que es el aprendizaje supervisado?
En los sistemas basados en el aprendizaje automático, el modelo funciona según un algoritmo. En el aprendizaje supervisado, el modelo se supervisa. Primero, se requiere capacitar al modelo. Con el conocimiento adquirido, puede predecir respuestas para las instancias futuras. El modelo está entrenado utilizando un conjunto de datos etiquetado. Cuando se otorgan datos fuera de la muestra al sistema, puede predecir el resultado. El siguiente es un pequeño extracto del popular conjunto de datos de Iris.
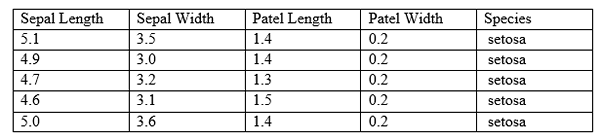
Según la tabla anterior, la longitud del sepal, el ancho de sepal, la longitud de la patel, el ancho de patel y las especies se denominan atributos. Las columnas se conocen como características. Una fila tiene datos para todos los atributos. Por lo tanto, una fila se llama observación. Los datos pueden ser numéricos o categóricos. El modelo recibe las observaciones con el nombre de la especie correspondiente como entrada. Cuando se da una nueva observación, el modelo debe predecir el tipo de especie a la que pertenece.
En el aprendizaje supervisado, hay algoritmos para la clasificación y la regresión. La clasificación es el proceso de clasificación de los datos etiquetados. El modelo creó límites que separaron las categorías de datos. Cuando se proporcionan nuevos datos al modelo, puede clasificar en función de dónde existe el punto. Los vecinos más nears (KNN) es un modelo de clasificación. Dependiendo del valor k, la categoría se decide. Por ejemplo, cuando K tiene 5 años, si un punto de datos particular es cerca de ocho puntos de datos en la categoría A y seis puntos de datos en la categoría B, entonces el punto de datos se clasificará como un.
La regresión es el proceso de predecir la tendencia de los datos anteriores para predecir el resultado de los nuevos datos. En la regresión, la salida puede consistir en una o más variables continuas. La predicción se realiza utilizando una línea que cubre la mayoría de los puntos de datos. El modelo de regresión más simple es una regresión lineal. Es rápido y no requiere parámetros de ajuste como en KNN. Si los datos muestran una tendencia parabólica, entonces el modelo de regresión lineal no es adecuado.
Esos son algunos ejemplos de algoritmos de aprendizaje supervisados. En general, los resultados generados a partir de métodos de aprendizaje supervisados son más precisos y confiables porque los datos de entrada son bien conocidos y etiquetados. Por lo tanto, la máquina tiene que analizar solo los patrones ocultos.
¿Qué es el aprendizaje sin supervisión??
En el aprendizaje no supervisado, el modelo no se supervisa. El modelo trabaja por sí solo, para predecir los resultados. Utiliza algoritmos de aprendizaje automático para llegar a conclusiones sobre datos no etiquetados. En general, los algoritmos de aprendizaje no supervisados son más difíciles que los algoritmos de aprendizaje supervisados porque hay pocas información. La agrupación es un tipo de aprendizaje no supervisado. Se puede utilizar para agrupar los datos desconocidos utilizando algoritmos. La agrupación K-mean y la densidad son dos algoritmos de agrupación.
algoritmo K-mean, coloca k centroide al azar para cada clúster. Entonces cada punto de datos se asigna al centroide más cercano. La distancia euclidiana se usa para calcular la distancia desde el punto de datos hasta el centroide. Los puntos de datos se clasifican en grupos. Las posiciones para los centroides k se calculan nuevamente. La nueva posición del centroide está determinada por la media de todos los puntos del grupo. Nuevamente, cada punto de datos se asigna al centroide más cercano. Este proceso se repite hasta que los centroides ya no cambian. K-Mean es un algoritmo de agrupación rápida, pero no hay una inicialización especificada de los puntos de agrupación. Además, existe una alta variación de los modelos de agrupación basados en la inicialización de los puntos de clúster.
Otro algoritmo de agrupación es Agrupación basada en densidad. También se conoce como aplicaciones de agrupación espacial basadas en densidad con ruido. Funciona definiendo un clúster como el conjunto máximo de puntos de densidad conectados. Son dos parámetros utilizados para la agrupación basada en densidad. Son ɛ (epsilon) y puntos mínimos. El ɛ es el radio máximo del vecindario. Los puntos mínimos son el número mínimo de puntos en el vecindario ɛ para definir un clúster. Esos son algunos ejemplos de agrupación que caen en el aprendizaje no supervisado.
En general, los resultados generados a partir de algoritmos de aprendizaje no supervisados no son muy precisos y confiables porque la máquina tiene que definir y etiquetar los datos de entrada antes de determinar los patrones y funciones ocultas.
¿Cuál es la similitud entre el aprendizaje automático supervisado y no supervisado??
- El aprendizaje supervisado y no supervisado son tipos de aprendizaje automático.
¿Cuál es la diferencia entre el aprendizaje automático supervisado y no supervisado??
Supervisado frente a aprendizaje automático no supervisado | |
| El aprendizaje supervisado es la tarea de aprendizaje automático de aprender una función que asigna una entrada a una salida basada en un ejemplo de pares de entrada-salida. | El aprendizaje no supervisado es la tarea de aprendizaje automático de inferir una función para describir la estructura oculta a partir de datos no etiquetados. |
| Funcionalidad principal | |
| En el aprendizaje supervisado, el modelo predice el resultado basado en los datos de entrada etiquetados. | En el aprendizaje no supervisado, el modelo predice el resultado sin datos etiquetados identificando los patrones por sí mismo. |
| Precisión de los resultados | |
| Los resultados generados a partir de métodos de aprendizaje supervisados son más precisos y confiables. | Los resultados generados a partir de métodos de aprendizaje no supervisados no son muy precisos y confiables. |
| Algoritmos principales | |
| Hay algoritmos para la regresión y la clasificación en el aprendizaje supervisado. | Hay algoritmos para la agrupación en el aprendizaje no supervisado. |
Resumen -Supervisado VS No supervisado Aprendizaje automático
El aprendizaje supervisado y el aprendizaje no supervisado son dos tipos de aprendizaje automático. El aprendizaje supervisado es la tarea de aprendizaje automático de aprender una función que asigna una entrada a una salida basada en un ejemplo de pares de entrada-salida. El aprendizaje no supervisado es la tarea de aprendizaje automático de inferir una función para describir la estructura oculta a partir de datos no etiquetados. La diferencia entre el aprendizaje automático supervisado y no supervisado es que el aprendizaje supervisado utiliza datos etiquetados, mientras que la inclinación sin supervisión utiliza datos no etiquetados.
Referencia:
1.TheBigDataUniversity. Aprendizaje automático - Supervisado frente a aprendizaje no supervisado, clase cognitiva, 13 mar. 2017. Disponible aquí
2."Aprendizaje sin supervisión."Wikipedia, Fundación Wikimedia, 20 mar. 2018. Disponible aquí
3."Aprendizaje supervisado."Wikipedia, Fundación Wikimedia, 15 mar. 2018. Disponible aquí
Imagen de cortesía:
1.'2729781' por GDJ (dominio público) a través de Pixabay


